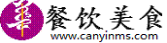

最新Claude2.1、Llama2随便用!亚马逊把生成式AI开发门槛打下去了
2024-01-05 本站作者 【 字体:大 中 小 】
好消息,搞生成式AI应用的门槛,被狠狠地打下去了!
就在最近,亚马逊云科技在年度盛会re:Invent中正式宣布:
在我这搞生成式AI应用,主流、最新大模型随便用~
例如Meta家的Llamau00a02u00a070B、Antropic家的Claudeu00a02.1等等:

能够将如此众多大模型“打包”起来的集大成者,便是亚马逊云科技的AI大模型服务Amazonu00a0Bedrock。
当然,其中也包含了自家最新升级的大模型Titan:
Titanu00a0Textu00a0Embeddings:将文本转变为数字表征;
Titanu00a0Textu00a0Lite:可执行对文本的总结、文案生成和微调;
Titanu00a0Textu00a0Express:开放式文本生成、会话聊天,并支持RAG;
Titanu00a0Multimodelu00a0Embeddings:支持搜索、推荐和个性化定制;
Titanu00a0Imageu00a0Generator:可生成超现实、影棚级质量的图片。
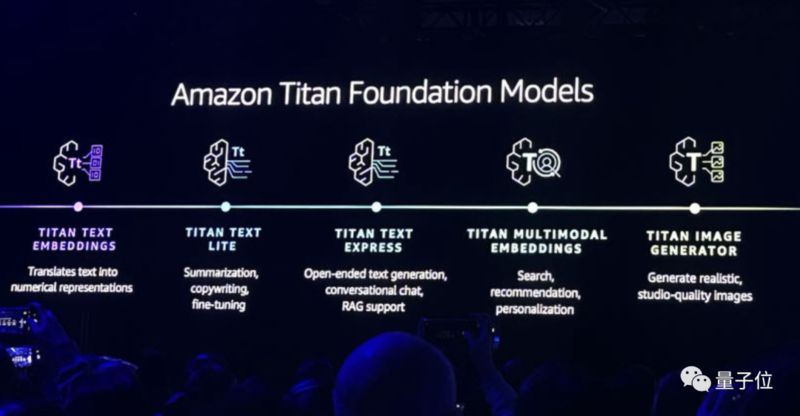
亚马逊云科技AI副总裁Swamiu00a0Sivasubramanian,还在现场演示了Titanu00a0Iamgeu00a0Generator的能力。
例如只需一句话就可以将一只绿色蜥蜴,毫无PS痕迹地变成橘色:
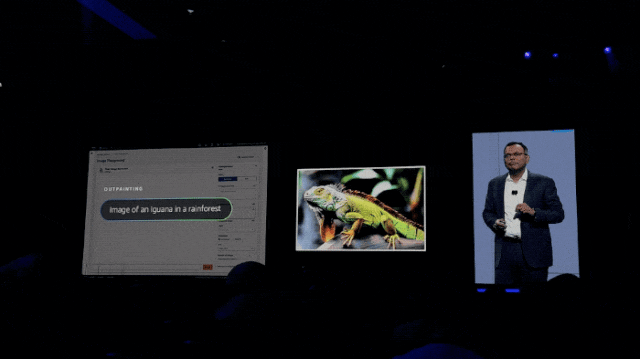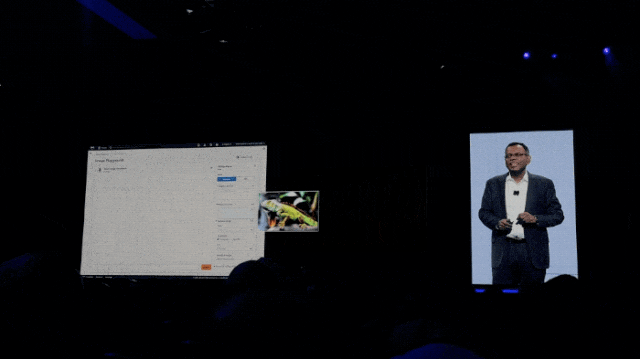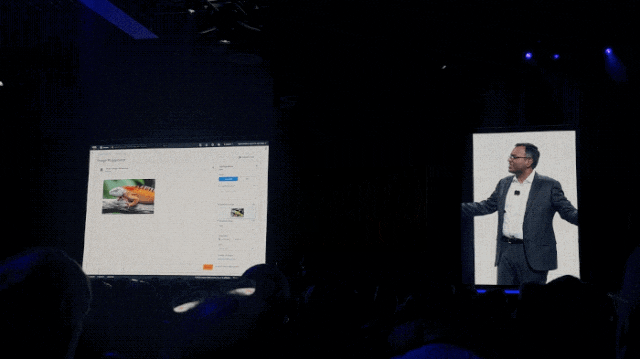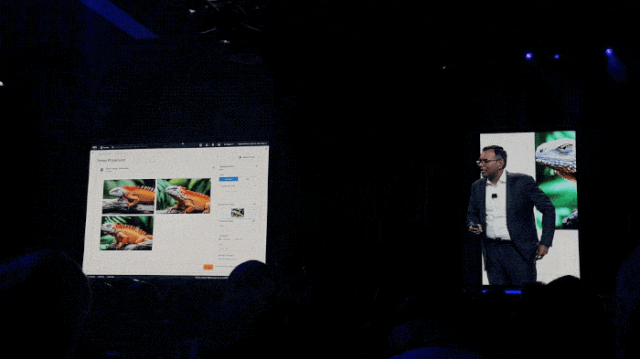
再如把图片掉转个方向,也是只是一句话的事儿了:

方便,着实是方便。
不过纵观整场发布会,这些个功能和升级也还仅是亚马逊云科技把门槛打下去的动作一隅。
还有更多新功能的发布,让搞生成式AI应用变得简单了不少。
SageMaker上新
SageMaker是亚马逊云科技长期押注的一个项目,它的主要作用便是构建、训练和部署机器学习模型。
Swami在今天的大会中宣布了它的诸多新功能,让客户可以更轻松地去构建、训练和部署生成式AI模型。
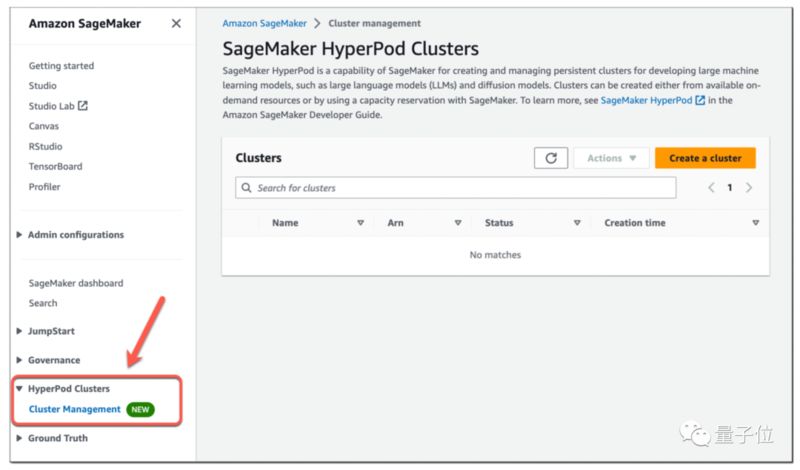
首先,便是SageMakeru00a0HyperPod功能。
我们都知道,以往基础模型通常过于复杂,无法使用单个u00a0AIu00a0芯片进行训练;因此,它们必须拆分到多个处理器上,这是一项技术上复杂的工作。
而SageMakeru00a0HyperPod可以提供对按需AI训练集群的访问,开发人员可以通过点击式命令和相对简单的脚本组合来配置集群,这比手动配置基础架构要快得多。
Swami在现场表示:
SageMakeru00a0HyperPod将训练基础模型所需的时间减少了40%。
SageMakeru00a0HyperPod不仅可以自动执行设置AI训练集群的过程,它还可以自动执行其维护。
当客户集群中的某个实例脱机时,内置的自动化软件会自动尝试修复它;如果故障排除尝试不成功,SageMakeru00a0HyperPodu00a0会将出现故障的节点换成新节点。
在某些情况下,基础模型需要数周或数月的时间来训练。如果中断使底层u00a0AIu00a0基础设施脱机,开发人员必须从头开始重新开始训练,这可能会导致严重的项目延迟。
为避免此类情况,SageMakeru00a0HyperPodu00a0会在训练期间定期保存AI模型,并提供从最新快照恢复训练的功能。
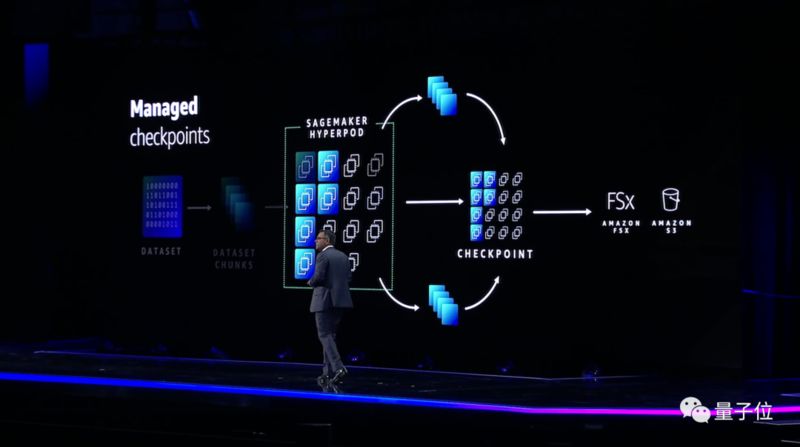
不仅如此,每个SageMakeru00a0HyperPod集群都预配置了一组亚马逊云科技开发的分布式训练库。
这些库会自动将开发人员的模型分散到集群中的芯片上,而且还可以将训练该模型的数据拆分为更小,更易于管理的部分。
其次,在推理方面,亚马逊云科技推出了SageMakeru00a0Inference功能。
它的出现将有助于降低模型的部署成本和延迟;新的推理功能可以让客户单个端点上部署一个或多个基础模型,并控制分配给它们的内存和加速器数量。
具体降本增效的成果,亚马逊云科技在现场也有介绍:
这项新功能可以帮助将部署成本降低50%,并将延迟减少20%。
在构建机器学习模型的无代码界面上的SageMakeru00a0Canvas也有所更新。
我们现在可以直接用自然语言去处理了!
在聊天界面中,SageMakeru00a0Canvas提供了许多与您正在使用的数据库相关的引导提示,或者你可以提出自己的提示。
例如,你可以通过说“准备数据质量报告”、“根据特定条件删除行”等等,让它来执行你的需求。
总而言之,SageMaker今天的众多能力更新,着实是让模型的构建、训练和部署简单了不少。
对数据也“下手”了
拥有强大的数据基础,对于充分利用生成式AI可以说是至关重要。
Swami在现场表示,强大的数据基础需要满足三点:全面comprehensive、集成integrated和治理governed。
围绕这些特性,亚马逊云科技在今天的大会中也做了相应新功能的发布。
首先便是针对向量引擎的OpenSearchu00a0Serverless,它能够带来更高效的搜索和流程。。

其次,DocumentDB和DynamoDB也加入到了向量功能,可以允许用户将多种数据存储在一起。

除此之外,MemoryDBu00a0foru00a0Redis也有了相应更新,它也可以支持向量搜索,响应时间变得更快,每秒可以处理数万个查询。

在分析数据库方面,亚马逊云科技则是推出了Amazonu00a0Neptuneu00a0Analytics,可以让开发人员在几秒钟内检查海量的图形数据,也支持更快的向量搜索。

在数据的“集成”特性方面,亚马逊云科技依旧坚持的是“zero-ETL”之道——Amazonu00a0S3加持下的OpenSearchu00a0Serviceu00a0zero-ETLu00a0integration,仅使用一个工具,便可以分析S3中的所有操作数据。
最后,在“治理”方面,亚马逊云科技上新的功能便是Cleanu00a0Roomsu00a0ML。

它可以允许用户在不共享底层数据的情况下与客户应用机器学习模型。
Oneu00a0Moreu00a0Thing
在推动大模型发展的这件事上,亚马逊云科技可以说是有着自己独到的“玩法”——
不仅发展自家的大模型,更是给其它大模型提供AI基础设施和AI工具,让它们也能更好地发展。
那么二者之间是否会存在冲突和竞争呢?
在量子位与亚马逊云科技数据库和迁移服务副总裁Jeffu00a0Carter的交流过程中,他发表了如下看法:
我希望我们生活在一个合作的世界里,每个LLM都擅长于不同的方面,我认为这种情况会持续下去,这种专业化水平也会持续一段时间。
我喜欢Bedrock的一个原因是它可以无缝地从一个LLM转换到另一个LLM。很明显,亚马逊将持续在LLM方面推进最先进的技术。
但对于每个LLM,或许下个月所呈现出来的能力会截然不同,这也就是为什么我们认为给客户提供选择的能力和同时使用多个功能的能力是如此重要的原因之一。
参考链接:1
本文来源:量子位

猜你喜欢

椰子蟹在哪个阶段可能会寄居在椰子壳中
 0
0 绝世好武功碧波潭宝箱怎么找
0 抖音文字找茬大师90后父母怎么过
0 我在疗养院送人上西天配置要求介绍
0 艾尔登法环褪色燃烧阎魔刀出招表
0 原神中那些可以控制敌人的方法控制系异常状态一览
0 AKB48授权盛大游戏AKB48樱桃湾之夏手游首曝预计明年上线
0 游戏系统功能“生化翻牌”中,每周需要完成几局生化模式就能解锁
0 逆水寒手游元素流碎梦装备推荐
0 第七史诗玩家需要了解的游戏开荒避坑知识,电游新手开荒必知
0 
太原市旅游攻略 太原最值得去的地方
密云古北水镇旅游攻略 密云古北水镇一日游攻略
银川沙湖旅游攻略 银川沙湖几月份去最好
黔东南旅游攻略 贵州黔东南旅游攻略自由行

青海湖旅游住宿攻略 青海湖环湖住宿攻略

丽江大理洱海旅游攻略 丽江大理攻略最佳旅游攻略

长春旅游攻略景点必去 长春市区旅游攻略必去景点
康定新都桥旅游攻略 新都桥必去的几个景点
普陀山自驾旅游攻略 普陀山旅游自驾游攻略

南昌旅游攻略景点必去 南昌必看的旅游点


